
基因
染色体是基因的载体。基因的基本单位是核酸。核酸分为脱氧核糖核酸(DNA)和核糖核酸(RNA)两类,都是由嘌呤和嘧啶两类碱基组成。一个核苷酸分子包括一个碱基、一个戊糖和一个磷酸。组成脱氧核糖核酸的碱基为:腺嘌呤(A)、鸟嘌呤(G)、胸腺嘧啶(T)和胞嘧啶(C)。组成核糖核酸的碱基除尿嘧啶(U)代替胸腺嘧啶(T)外,其余碱基相同。戊糖与碱基相连形成核苷(nucleoside),核苷的戊糖侧链与磷酸结合,形成核苷酸(nucleotide)。四种不同碱基就形成四种核苷酸。核苷酸分子间以3'、5'-磷酸二酯键相连,形成DNA或RNA的多聚核苷酸分子(polynucleotide)。分子中保留的5'游离磷酸基(称为5'端)和游离羟基(称为3'端)。两条多核苷酸链相互作反方向(5'→3'和3'→5')缠绕,形成双螺旋结构,戊糖和磷酸在外侧,碱基在内侧,碱基间以A~T和G-C方式配对,这就是DNA分子的基本构型。RNA分子是单链结构,但是部分区域也可以呈A-U和G-C配对,形成局部次级双链结构。按RNA的功能,RNA可分为信使核糖核酸(mRNA)、转运核糖核酸(tRNA)和核糖体核糖核酸(rRNA)。
基因的主要特征
基因(gene)是负载着特定功能的DNA片段,是遗传的基本单位。它的主要特征为:①能复制成两条相同的DNA,这是细胞分裂的基础;②基因通过转录成mRNA,再翻译成多肽链(形成蛋白质或酶),遗传信息通过此途径决定某种生理或病理性状;③基因可发生突变,这是遗传病、遗传易感性和遗传多态性产生的基础。
基因的分类
基因按其功能分为:①结构基因(structural gene),即编码蛋白质的基因,有转录和翻译功能;②调控基因(regulatory gene),即它本身不转录而对结构基因的表达起调控作用,包括启动基因和操纵基因;③只有转录作用而无翻译功能的基因,如tRNA基因和rRNA基因。
基因可根据所在部位分为:①核内基因,细胞核内的基因,是主要部分;②核外基因,即指线粒体基因(mitochondral DNA,mtDNA)。
基因还可以根据其生物来源分为:①原核基因,即单核细胞生物的基因,它一般只有一个染色体,即一个DNA(或RNA)分子,多呈环状;②真核基因,即包括人类在内的高等生物基因。染色体大都成对,基因呈超螺旋线状排列其上。
结构基因的大小相差很大。可以分为:①小型基因,如α珠蛋白基因(0. 8kb)、β珠蛋白基因(1. 5kb);②中型基因,如蛋白C基因(11kb)、白蛋白基因(25kb)、第Ⅸ因子基因(34kb);③大型基因,如苯丙氨酸羟化酶基因(90kb);④巨型基因,如第Ⅷ因子基因(186kb);⑤庞大基因,如肌萎缩性蛋白基因(DMD>2Mb)。
结构基因常分为不同区段:
编码区:大多数真核细胞的编码区都分为外显子(exon)和内含子(intron)。编码的外显子被非编码的内含子分隔开,故内含子数目为“外显子数-1”。一般内含子的核苷酸比外显子多许多倍。在转录为前mRNA时,内含子参与,但进入胞质前,内含子的转录部分被切除,外显子部分拼接,形成成熟的mRNA,内含子的5'端一般为GT,3'端为AG,这是剪切的识别信号。
前导区:又 称5'非编码区(5'-UTR),通常在第一外显子的外侧(上游)的一段非编码区。
尾区:最末一个外显子的外侧(下游)的一段非编码区。
调控区:此区有①启动子(promoter),是转录启动信号所在部位,包括第一外显子上游-30~-50bp处的TATA框(TATA box),为RNA聚合酶的结合处,是转录起始点;上游-80~-100bp处为CAAT框(CAAT box),也是一个RNA聚合酶的结合点,控制起始转录的频率,此外,还有一些抑制转录的顺序;②增强子(enhancer),这段顺序有增强转录的作用,有组织特异性;③沉默子(silencer),是启动子的负调控元件,能对某些激活因子起阻遏作用,具有抑制基因转录的功能;④绝缘子(insulator),对基因转录起分闸作用,阻止激活或阻遏作用在染色质上的传递。如果它位于增强子和启动子之间,可以阻止增强子对启动子的激活;如果位于活性基因与异染色质之间,可以保护该基因免受异染色质化而失活。⑤终止子(terminator),在基因的末端,有终止转录的功能。
基因的复制
在细胞分裂时,染色体分裂为两条染色单体(chromatid),本质上是DNA复制成两条完全相同的DNA。其过程是,DNA的两条多核苷酸链裂开,每条链以自己为模板,按照碱基配对原则(A-T配对、G-C配对),合成各自的新链,这样,每条DNA保留一条旧链,故称为半保留复制。
基因的表达
基因表达(gene expression)是指DNA顺序中蕴藏的遗传信息转变为蛋白质的过程。分下列步骤:①转录(transcription),系以一条多核苷酸链(sense strand,有意义链)为模板,在RNA聚合酶的作用下,从TATA框和CAAT框起始,按碱基互补原则,合成一条RNA链。此过程与复制不同处是,转录只在一条多核苷酸链进行,故合成的RNA是单链,其次,与A互补的碱基是U不是T,最后,参与合成的酶是RNA聚合酶,而不是DNA聚合酶。新转录的RNA称前mRNA,在进入细胞质前,内含子被切除,外显子拼接成为成熟的mRNA后,进入细胞质进行翻译;②翻译(translation),是指mRNA上的遗传信息指导蛋白质合成的过程。所谓“指导”是指合成多肽链氨基酸数目和顺序是由mRNA上的碱基顺序来决定的。在DNA或mRNA上的3个相连的碱基决定一个相应的氨基酸,这就依靠遗传密码(genetic code)。ATG是甲硫氨酸密码,是合成多肽链的启动信号,而UAA、UGA、UAG为终止密码,为多肽链合成的终止信号。tRNA和rRNA都是在翻译过程中起作用。翻译后还要进行加工(post-translational processing),如肽链的切断、聚合、氨基酸的羟基化、磷酸化、乙酰化、糖基化等,最终才能具有一定功能的蛋白质。
基因表达是一个非常复杂的过程。在基因的旁侧甚至内含子部分都有各种调节表达的顺序。起着促进和抑制、加速和延缓蛋白质合成的作用。
人类基因组
一个细胞中所含有的全部基因总和称为基因组(genome)。人类基因组约含3. 2×109个核苷酸。根据从低等动物的推算,原来估计入类有50 000~100 000个基因。但最新资料表明,大约只有20 000~25 000个基因。其中结构基因占基因组的2%~3%,其他为基因间的间隔顺序、基因内插入顺序、重复顺序等。
核内基因组
单一序列(unique sequence):一般仅有单一或几个拷贝,大多数编码蛋白质和酶的基因属于此类。
重复序列(repetitive sequence):指在基因组中有多个相同的序列。又可分为:①高度重复序列(highly repetitive sequence),其长度可以是2、4、6、8等几个碱基,较长的达200bp,但重复拷贝数可达106次以上。如染色体着丝粒、端粒和Y染色体长臂上的异染色质区就是由高度重复序列的卫星DNA (satellite DNA)构成。②中度重复序列(moderate repetitive sequence)位于单一序列之间,重复10~1000次,rRNA、tRNA及组蛋白基因属于此类。
基因家族和基因簇(gene family and gene cluster):来源相同、结构相似、功能相关的这类基因称为基因家族。基因家族的成员可分布于几条不同的染色体上,也可紧密连锁于一条染色体上,成串排列形成一个基因复合体,后者称为基因簇。如人类白细胞抗原(HLA),A-C-B-D-DR-DQ-DP七个座位排列在6p21. 3上,形成一个基因簇。
假基因(pseudogene):基因家族中有些成员,有许多同源顺序,但不能产生有功能的基因产物,这些基因可能在进化过程中发挥过作用,称为假基因。如珠蛋白基因的α和β链上都有这种假基因。
线粒体基因组
人类线粒体DNA(mitochondrial DNA,mtDNA)系独立于细胞核染色体外的又一基因组,由16 569个碱基对组成。mtDNA为环状双链DNA分子,基因组含37个基因,其中13个蛋白质基因,2个rRNA基因,22个tRNA基因。mtDNA具有下列特点:①排列紧密,不含内含子。基因间隔很短,甚至没有间隔,有的基因还有重叠。每个基因有多个拷贝。②mtDNA的突变率高于核内DNA。③mtDNA为母系遗传。④部分mtDNA的密码子不同于核内DNA的密码子。如UGA不是终止密码而是色氨酸密码。又如AGA、AGG不是精氨酸密码,而是终止密码。
人类基因组计划
人类基因组约有3. 3×109个核苷酸。人类基因组计划就是要将基因组全部碱基排列顺序“读出”,并了解它们的功能,即“读懂”。亦即弄清基因组的结构和功能,以达到对人类基因组完整和系统的认识,这将对临床医学、生命科学、生物工程学具有无可估量的理论意义和实践价值。而且新技术的建立也将有利于生命科学其他领域的研究。
1985年美国首先提出入类基因组计划(Human Genome Project,HGP),引起各国政府和学者广泛关注,并成立了国际性组织——HUGO(Human Genome Organization),有超过1000位学者参加了此项工作。英国、德国、法国、日本和我国都开展了这项研究。美国1990年开始实施,预计三个五年计划(1991~2005)完成。由于新技术不断发展,包括识别8~10个碱基的内切酶的应用、克隆大片段DNA的载体如YAC(酵母人工染色体)、BAC(细菌人工染色体)和MAC(哺乳类人工染色体)的应用、基因定位技术的发展、新的遗传标记如微卫星DNA(STR)、序列标记位点(sequence tagged sites,STSs)、单核苷酸多态(single nucleotide polymorphism,SNP)、表达序列标记(expression sequence tags,EST)等的使用,特别是DNA测序技术的快速发展(每秒读出1000个碱基),使1990~2005年的计划,在2003年已经完成。但在2000年6月,克林顿和布莱尔突然向全世界公开宣布HGP已经完成。原来,在美国有一个Celera基因公司,首席科学家Craig Venter教授,采用了独特的DNA测序路线,即鸟枪法(shotgun),从1998年9月开始,居然在不到两年就基本完成了人类基因组的全部顺序测定,并且声称要立即公布科研成果。使得官方的研究机构非常被动和尴尬,经过协商,官方承认此私人机构的成果,与HUGO成员的结果一起公布。Venter教授功绩被肯定。
基因组草图的完成对人类带来的影响:根据克林顿技术顾问的总结,基因组草图的完成,有下列所述的几方面意义:①对人类疾病(大多数,尽管不是全部)的诊断、预防和治疗都会带来划时代的变化。它开创了生物医学的新纪元。给人们带来新的方法去预防、诊断、治疗以至治愈疾病。人类已经有5000种以上已经确认的遗传病,是由某个基因缺陷造成,还有成千的疾病由基因缺陷的影响而产生。过去,人们要将某个基因与某一疾病联系起来要经历艰辛的过程。而现在能够大大加快。例如,囊性纤维化基因在1989年用了9年时间去克隆,而今只需9天就定位了帕金森病基因。②预测患某种疾病的风险和预测疾病发展过程。通过从基因水平筛查,用改善食物或生活方式来预防疾病。③基因诊断可以对疾病作出准确诊断。许多疾病具有异质性,即可以由于不同基因的突变分出若干亚型。现在可以针对亚型制订诊断方案,使治疗变得更为有的放矢。④基因治疗:在分子水平探讨新的治疗方法。在许多情况下,不一定要用正常基因取代致病基因,更简单而有效的方法是用正常的基因产物(蛋白质)去取代有缺陷的蛋白质。此外,也可以用一种小分子化合物与异常蛋白质作用以改变其生物活性。还可以合成一种药物来封闭由基因缺陷合成的异常蛋白,目前慢粒正在试用这种模式治疗。⑤人类基因组的破译带动了许多动物、植物的基因组的绘制,因为生物基因组的序列有许多是相同的。
从人类基因组草图的初步分析中,还见到几个有趣的现象:①据原来估计,人类有50 000~100 000个基因。但最新资料表明,人类仅有20 000~25 000个基因,超过低等动物的基因数目并不多(果蝇为13 600个);②人类基因约有一半是由细菌的转座子而来,即所谓“水平传递”,与过去认为完全由遗传“垂直传递”大相径庭;而这种转座到人类DNA转座成分活性大大降低;③在近着丝粒和端粒旁的节段重复(segmental duplications)特别多;④在有丝分裂中,男性突变率是女性的2倍;⑤重组率高的区段多在染色体的远端,特别是短臂远端;⑥人类和类人猿的DNA顺序有99%是相同的,另外那不相同的1%可能是人区别于动物的关键部分。以上现象的解释和意义还需大量研究工作来说明。
人类基因组计划草图的完成意味着后基因组世纪(postgenomic era)已经开始。从生物医学(biomedicine)的不同层次,可以将这一转变归纳如表:
从人类基因组计划到后基因组世纪的标志性转变

后基因组时代值得特别提及的几项主要工作是:
一、继续完成测序工作:目前公布的基因组草图中还有一些顺序未被公认,需要进一步证实;有些序列缺口区测序难度大,没有完成;模式动物的基因组测序尚未完成。目前模式生物已经由原来的6种增加到60种,估计将会增加到100种以上。模式生物研究的意义已经远远超过过去的估计,它可以帮助人们发现以人类新的、复杂的和转瞬即逝的代谢途径和人类基因功能学,也促进了进化基因组学的研究。
二、功能基因组学:即利用基因组草图寻找人类基因组中全部基因,包括目前已知的几千种致病基因,克隆这些基因,研究其结构、功能和调节,阐明它们编码的蛋白质,它们与哪种或哪些疾病有关,是决定某种遗传病的基因,抑或是影响某种疾病发生的易感基因?这将对疾病的预防、诊断、治疗带来新的突破。蛋白组学将成为基因功能学的核心。所谓“蛋白质组(proteome)”即生物拥有的全套的蛋白质。“蛋白质组学”即研究生物全套蛋白质方方面面的学科。它不仅包括蛋白质的定性和定量,而且研究蛋白质的定位、修饰、活性和蛋白质间的相互关系与相互作用。上面提到,人类基因组的编码基因数量仅为低等生物的一倍多,然而人类各种类型细胞和组织的各种功能的复杂程度,远非其他生物可比。合理的解释和有限的资料表明:①一个基因可有不止一个转录本,编码出不同的蛋白质;②蛋白可以有不同的剪切部位,因而肽链的功能在不同组织中可以不同;③转录后有许多种不同的修饰,如磷酸化、糖基化、乙酰化、硫酸化等;④一个蛋白质复合体的肽链组成可以来源于多个基因;⑤一个蛋白质可以有不止一种功能;⑥一个蛋白质可以有多种调节方式,显示出不同的作用和时空表达特异性。这样,估计20 000多个结构基因可以编码出约90 000种蛋白质。
过去,人们用传统的方法研究了成千个蛋白质,包括代谢和信号传导蛋白,复制、转录和翻译过程中的蛋白,分泌和细胞骨架蛋白,以及其他细胞复合成分。基因组草图的完成要求人们用全新的方法如大型质谱分析、酵母双杂交技术(yeast two-hybrid technique)、微阵列技术(microarray)、自动化技术以及新的系统生物学(systems biology)方法,才能使蛋白质组的研究有新的发现和更快的进展。
后基因组世纪的一个重要方面是寻找致病基因,包括单基因病基因和疾病易感基因。从1981~2000年已经找到1112个致病基因和疾病相关基因,还有94个与肿瘤易位和融合有关的基因。1986年起都以遗传图为基础,用位置克隆(positional cloning)方法来克隆基因。不仅单基因病而且多基因病如1型糖尿病和哮喘也已获得有价值的结果。但是到了基因组草图完成后,现在已经和最终将用直接测序来取代位置克隆。即所谓“先定位,后克隆”到“个人基因组全测序”。
功能基因组学的另一重要研究内容是解析基因非编码区的功能,这是ENCODE计划的重要研究内容,为基因的调节元件的鉴定以及表观遗传学(epigenetics)研究提供重要资源。
三、研究人类基因组多样性:即各人种间的大约有0. 1%的碱基差异。这集中表现为单核苷酸多态性(single nucleotide polymorphisms,SNPs),即在不同人种间,在平均约100~200bp的距离,就有一个特异的单个碱基差异,由此形成了多态性。SNP将成为21世纪研究的一个重点,不同种族的HapMap计划为人类基因组多样性研究提供了重要的资源。因为它不仅作为新的更加精确有用的遗传标记,而且这种变异(当然也包括其他变异)还影响和调节表型,包括外形、细胞、组织和器官的内在过程,目前被广泛用于疾病基因易感性的关联分析。同时在复杂性状(complex trait)的鉴定中,提出了“常见疾病——常见等位基因(common disease,common allele)”的学说,SNP将在这些常见疾病的研究中发挥重要作用。除SNP外,最近引人关注的拷贝数目多态性(copy number polymorphisms,CNPs)在疾病发生、关联分析、基因进化与漂移等研究中得到越来越多的应用。
四、个体基因组学:自2007年以来,单个个体基因组序列已陆续发布,如著名科学家J. Craig Venter和James D. Watson,以及一名中国汉族和一名尼日利亚非洲裔的个人基因组,这得益于新一代基因组测序技术和比较基因组学技术的发展和应用。尤其值得一提的是,通过对一名患有急性髓性白血病患者的个体基因组测序发现了10种可能导致白血病的基因突变。预计随着测序成本的降低,个体基因组测序将在致病基因的发现、基因诊断、个体识别等领域得到更多的应用。
五、表观遗传学:虽然人类基因组计划解析了人类基因组的结构和组成特点,但仍然无法解释某些控制性状或疾病的遗传规律。与经典遗传学不同的是,表观遗传学主要研究DNA的甲基化与去甲基化修饰、非编码RNA、不同组蛋白修饰(如甲基化、乙酰化等)组成的组蛋白密码(histone code)以及蛋白质修饰等对遗传性状的控制规律。尤其是非编码RNA和组蛋白密码的研究成为目前的研究热点。
六、基因组带来的有关基因信息学、社会学、法学、民族学、伦理学问题以及知识产权带来的商业竞争问题,也将成为社会共同关心的问题。
基因突变
基因突变是指基因的核苷酸顺序或数目发生改变。突变可发生在体细胞,也可发生在生殖细胞,但后果有所不同。突变可自然发生,称自发突变(spontaneous mutation),也可人工诱变(induced mutation or mutagenesis)。通常见到的突变,都是自发突变。但遗传病的突变大多数不是个体或生殖细胞成熟过程中发生,而是遗传而来。
突变的分类方法很多。一般可以粗分为二大类:即点突变(point mutation)和节段性突变(segmental mutation)或长度突变(length mutation)。后者包括某一节段DNA的缺失、重复、倒位、插入等。实际上,点突变(point mutation)是一个沿用已久但比较模糊的概念。大多数情况它指单个碱基的改变,但过去对几个碱基的缺失也称为点突变。如至今将β地中海贫血的41-42(-4bp),缺失了4个碱基,仍然称为点突变;相反,在G-6-PD缺乏症中,3~5bp的缺失已经归入微小缺失突变。突变也可按基因表达的结果或(和)基因产物蛋白质的结构改变来划分。有些突变影响蛋白质“质”的改变,导致不同的表型效应。如镰形细胞贫血、高铁血红蛋白血症等,这类突变约占50%~60%,另一类则表现为表达量的变化,如合成蛋白质量的不足或易于降解,如各型地中海贫血。也可以是突变后表达量增加,如某些癌基因的突变。按DNA碱基顺序的改变,可以分为:①单个碱基置换(base substitution);②移码突变(frame-shift mutation);③整码突变(codon mutation);④不等交换(unequal crossing over)。而单个碱基置换又可根据其效应分为:同义突变(same sense mutation)、错义突变(missense mutation)、无义突变(nonsense mutation)、终止密码突变(stop codon mutation)、抑制基因突变(suppressor gene mutation)等。
McKusick按突变在转录或翻译阶段的部位不同,将突变分为:
一、转录突变(transcription mutation),其中包括:
- 启动区突变,有几种β+地中海贫血和乙型血友病Leyden属此类;
- RNA剪切突变,可改变5'或3'端内含子的剪切点,也可以建立新的剪切部位,如β地中海贫血的内含子Ⅱ654(C-T)突变;
- 多聚A尾信号部位突变,如β+地中海贫血mRNA多聚A加尾信号AATAAA→AACAAA,导致β转录本延长而不稳定;
- 加帽部位突变(cap site mutation),在β+地中海贫血也可见到;
- 调控顺序突变,如增强子、抑制顺序等的突变。
二、翻译突变(translation mutation),包括各种编码区突变,如起始密码子ATG突变,见于Hb South Florida,以及前面提到的移码突变、错义突变、无义突变、终止密码突变等。
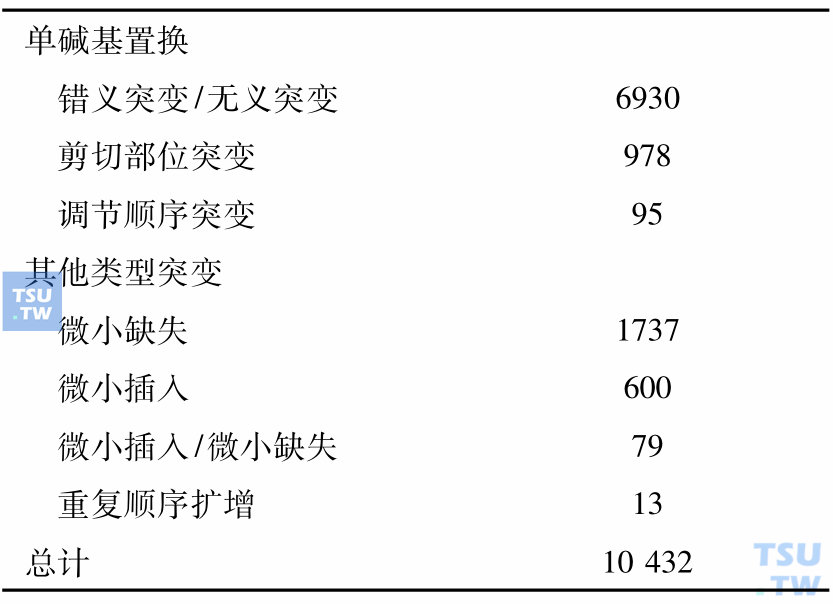
三、突变导致mRNA或蛋白质不稳定,如易位或其他重排带来的加强或抑制的位置效应(position effect)。如各种白血病的易位后引起的基因移位效应;又如Hb Lepore的各种类型融合基因(fusion genes)。各种突变所占比例相差很大,根据一项统计,下表中列出各种突变所占比例。
619个基因统计出的各种突变数
引自:David Cooper and Michael Krawczak,1997
